
Vector Databases Unlocked: Your Key Next-Gen AI Search
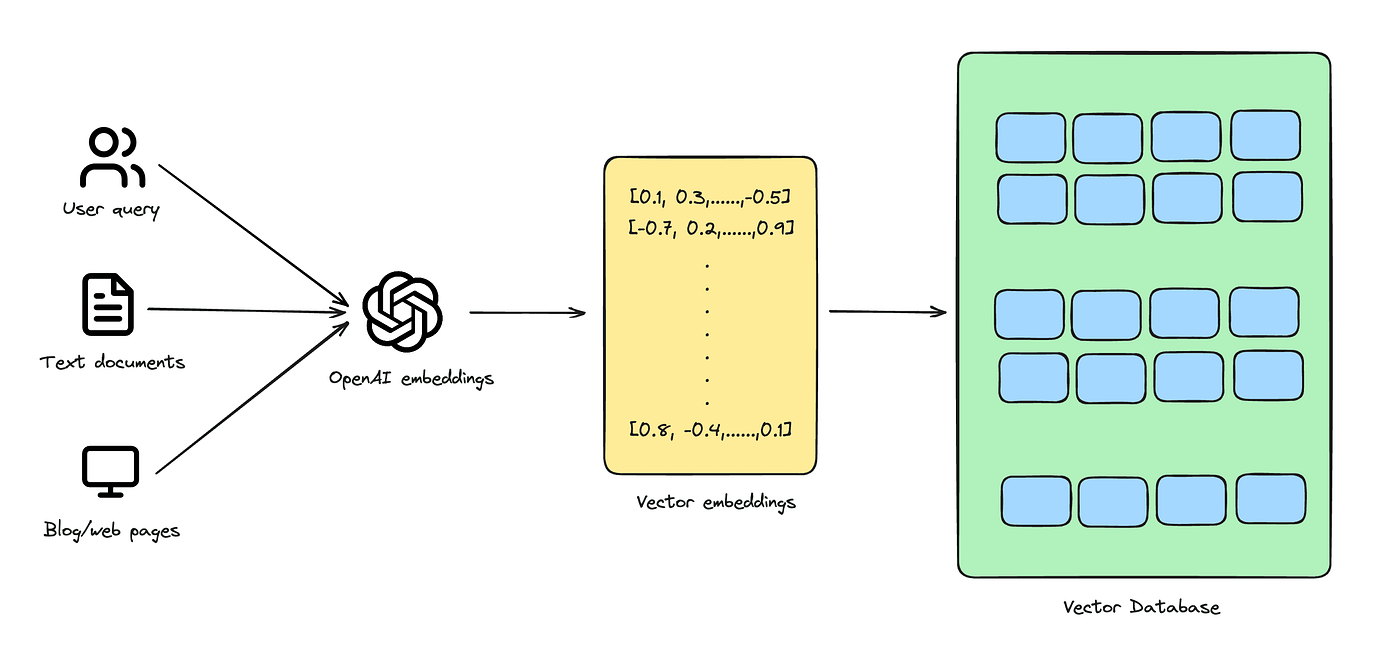
Vector databases store numeric “meaning” (embeddings) & let you search by similarity rather than exact text.


In today’s AI-driven world, terms like semantic search, vector embeddings, and retrieval-augmented generation (RAG) are becoming part of everyday tech vocabulary. I follow most of the AI techies on X [Twitter]. I mean, every other day I see something related to Vector DB.
Vector database — a powerful, behind-the-scenes engine that makes AI smarter, faster, and more context-aware.
In this post, I’ll walk you through what a vector database is, how it works, why it’s important, and how it compares to traditional databases. Covers the theory, compares tools, shows real use cases, and includes a practical Python tutorial using Sentence-Transformers + Qdrant (local).
Please, your support means a lot to me. Claps would help this blog reach more people. I have spent a good amount to write this. Hopefully it reaches to all who are searching to learn Vector DB. Read my other blogs here:
Let’s start with vectors
A vector, in the context of AI, is a numerical representation of data. It could be a sentence, an image, or even an audio clip — converted into a long list of numbers (often 100 to 1,000+ dimensions) that captures its meaning or features.
Let’s take an example:
“Paris is the capital of France.” → [0.13, 0.92, -0.34, …, 0.45]These are called embeddings, and they’re the reason LLMs can understand the semantic similarity between “Paris” and “London” better than just comparing strings.
But storing and searching through millions of these high-dimensional vectors isn’t what traditional databases (like MySQL or MongoDB) were built for.
That’s where vector databases come in.
What is a vector database?
A vector database is a purpose-built system designed to store, index, and search through vector embeddings efficiently — especially at scale.
Unlike traditional databases that match rows or columns, vector databases return results based on semantic similarity.
Here’s what that means:
Traditional DB: Find “apple” == “apple”
Vector DB: Find “apple” ≈ “fruit,” “granny smith,” “orchard”
Embeddings are usually produced by models like transformers (BERT family), CLIP (for images + text), or Sentence-Transformers for sentence-level embeddings.
How vector databases actually work (indexing, ANN, distance metrics)
The core problem: nearest neighbour search
Given a query vector, find the most similar vectors in a large collection. Brute force compares the query to every vector (O(n) time) — slow when n is millions. Vector DBs solve this using Approximate Nearest Neighbour (ANN) techniques and optimized indexing.
ANN algorithms (theory, briefly)
It’s a type of nearest neighbour search and a technique used in vector databases to find data points closest to a given query point with a certain level of approximation.
Unlike exact nearest neighbour searches, ANN focuses on speed and efficiency, accepting a small degree of approximation for significantly faster results. This approach is particularly effective in high-dimensional spaces, typical in modern AI applications, where exact matching is computationally intensive.
E.g., image recognition systems. (ANN can analyze an image, convert it into a vector, and compare it to a database of image vectors.) , Music streaming services, Medical imaging.
Steps involved:
HNSW (Hierarchical Navigable Small World) — builds a layered proximity graph to navigate quickly from coarse to fine neighborhoods. Many modern vector DBs use HNSW as a default for its strong speed/accuracy tradeoffs.
IVF (Inverted File) and Product Quantization (PQ) — commonly used in FAISS and some DBs to compress vectors and shard search space.
ScaNN, Annoy, LSH — other options, chosen based on size, accuracy needs, and memory constraints.
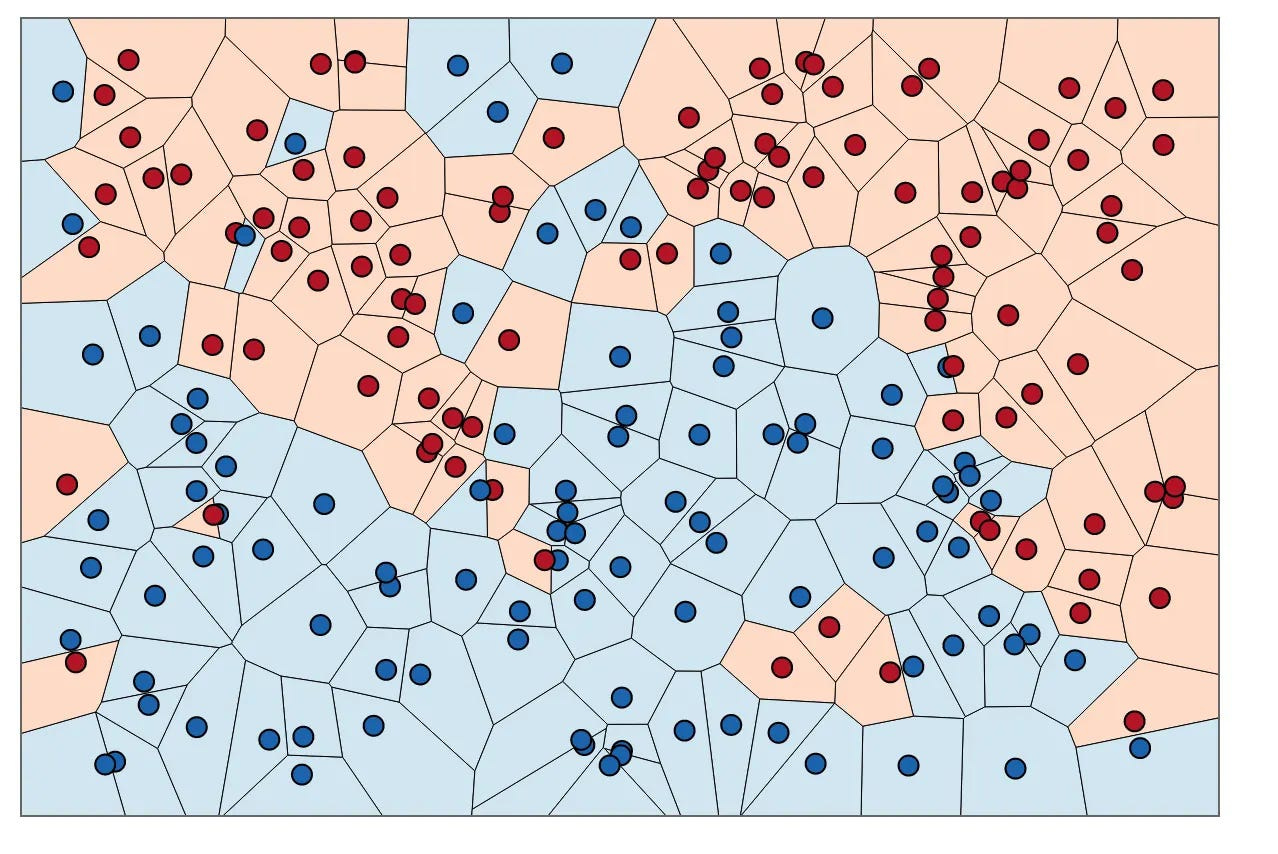
Similarity metrics
Vectors can be represented as lists of numbers or as an orientation and a magnitude. For the easiest way to understand this, you can imagine vectors as line segments pointing in specific directions in space.
Let’s check how to calculate it?
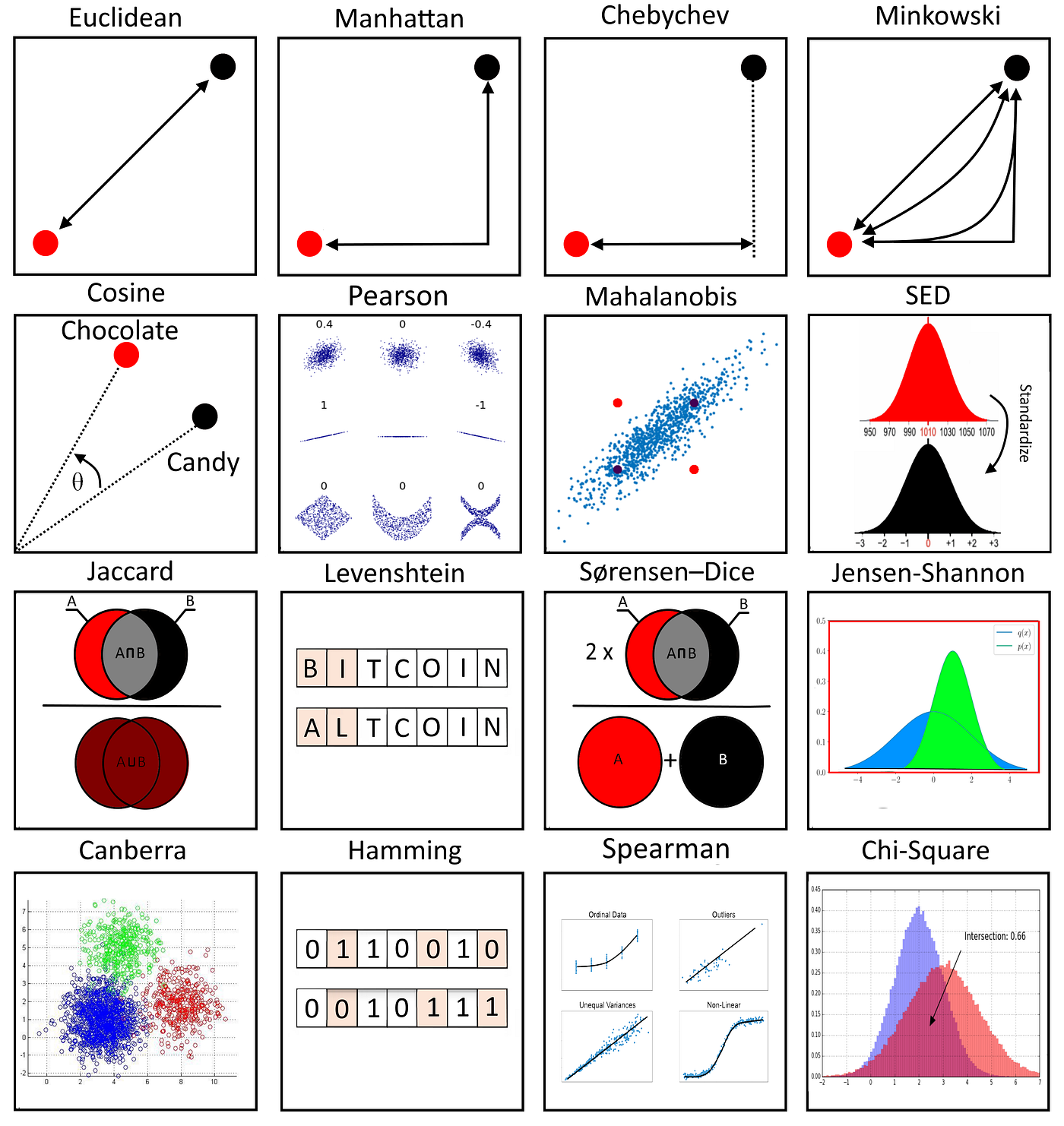
There are several ways to calculate the similarity (or distance) between two vectors, which we call metrics. The most popular ones are:
Dot Product: Obtained by multiplying corresponding elements of the vectors and then summing those products. A larger dot product indicates a greater degree of similarity.
Cosine Similarity: Calculated using the dot product of the two vectors divided by the product of their magnitudes (norms). Cosine similarity of 1 implies that the vectors are perfectly aligned, while a value of 0 indicates no similarity. A value of -1 means they are diametrically opposed (or dissimilar).
Euclidean Distance: Assuming two vectors act like arrows in vector space, Euclidean distance calculates the length of the straight line connecting the heads of these two arrows. The smaller the Euclidean distance, the greater the similarity.
Manhattan Distance: Also known as taxicab distance, it is calculated as the total distance between the two vectors in a vector space, if you follow a grid-like path. The smaller the Manhattan distance, the greater the similarity.
{kind=link}
{kind=link}
and many more. One of the best place to know about this here.
Purpose-built vs extension-based vector databases
Purpose-built vector DBs
Examples: Qdrant, Pinecone, Weaviate, Milvus, Chroma. They:
Optimize ingestion, indexing, filtering, and ANN out of the box.
Offer features like metadata filtering, hybrid search (vector + scalar filters), multi-vector per record, and scaling options
They are best for production RAG, recommendation engines, and high-query workloads.
Extensions on traditional DBs
Examples: PostgreSQL + pgvector, Redis Vector Search, Elasticsearch with vector modules.
Good if you already run PostgreSQL or Redis and want to add vector search without introducing a new system.
May trade off some ANN performance or advanced features compared to purpose-built systems. Still a smart choice for simpler use cases or when ACID compliance is critical.
Popular systems — short, researched comparison
Pinecone — a fully managed, serverless vector DB with auto-scaling and enterprise integration. Great for RAG in production. Pinecone
Qdrant — open-source, Rust-based, great performance and filtering; easy local quickstart with Docker. Good for building production-ready systems while keeping control.
Weaviate — open-source with a GraphQL front-end — supports built-in ML modules and knowledge-graph-style features.
pgvector (Postgres) — adds vector column + similarity functions to PostgreSQL; ACID, SQL familiarity. Great for teams already in Postgres.
Milvus, Chroma, and FAISS — Milvus for large distributed GPU workloads; Chroma for local LLM workflows; and FAISS is a library used inside other systems for ANN. (FAISS is not a full DB by itself but a foundational library.)
Real-world architectures and use cases
RAG (Retrieval-Augmented Generation): Index documents as embeddings in the vector DB; at query time, retrieve top-K documents and pass them as context to your LLM. Popular pattern for building chatbots with long context. (Pinecone + OpenAI is a common combo in tutorials.)
Recommendation engines: For “people who liked this also liked…,” compute user and item embeddings and perform nearest neighbor queries.
Multimodal search: CLIP embeddings for images and text allow cross-modal search (text → images and vice versa).
Hybrid search: Combine vector retrieval with keyword/SQL filters (e.g., “top-10 similar articles from 2024 only”).
HANDS-ON TUTORIAL — Build a local semantic search with Sentence-Transformers + Qdrant
This is a compact, runnable tutorial. We’ll:
Install dependencies.
Run Qdrant locally via Docker.
Generate embeddings with Sentence-Transformers (
all-MiniLM-L6-v2).Index documents into Qdrant.
Query similar documents.
Why this stack? Qdrant has an excellent local quickstart and Python client; Sentence-Transformers provides easy, quality embeddings for semantic search. Both have well-documented guides.
My Suggestion: This tutorial is local/educational. For production, consider secure managed instances, bigger models, and batching with async upload.
A. Setup (commands)
Run in terminal:
# create a virtual env (optional)
python -m venv venv
source venv/bin/activate# install Python libs
pip install qdrant-client sentence-transformers numpy uvicorn fastapiStart Qdrant locally (Docker recommended):
# start a Qdrant container (requires Docker)
docker run -p 6333:6333 -p 6334:6334 qdrant/qdrantB. Example dataset
Create a small sample corpus (Python list) — in real life you’d use articles, product descriptions, or PDFs.
documents = [
{"id": "1", "text": "How to cook perfect pancakes: recipes and tips."},
{"id": "2", "text": "Best practices for PostgreSQL performance tuning."},
{"id": "3", "text": "A beginner's guide to machine learning and neural networks."},
{"id": "4", "text": "Top 10 travel destinations for food lovers in 2025."},
{"id": "5", "text": "Understanding vector databases and semantic search."}
]C. Encoding + Uploading to Qdrant (full Python script)
# filename: qdrant_semantic_search.py
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams
from sentence_transformers import SentenceTransformer
import numpy as np# 1 Connect to local Qdrant
client = QdrantClient(url="http://localhost:6333")
# 2 Create collection (if not exists)
collection_name = "demo_docs"
if collection_name not in [c.name for c in client.get_collections().collections]:
client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=384, distance=Distance.COSINE) # using all-MiniLM-L6-v2 -> 384 dims
)
# 3 Load the embedding model
model = SentenceTransformer("all-MiniLM-L6-v2") # quick, small, effective
texts = [d["text"] for d in documents]
# 4 Encode
embeddings = model.encode(texts, show_progress_bar=True, convert_to_numpy=True)
# 5 Upload (batch)
points = []
for doc, emb in zip(documents, embeddings):
points.append({
"id": int(doc["id"]),
"vector": emb.tolist(),
"payload": {"text": doc["text"]}
})
client.upsert(collection_name=collection_name, points=points)
print("Uploaded", len(points), "documents to Qdrant.")We used
all-MiniLM-L6-v2(384-dim) as a fast, small model suitable for demos; Sentence-Transformers offers many models depending on accuracy vs latency needs.A Qdrant collection was created
Distance.COSINEto match cosine similarity, common for sentence embeddings.
D. Querying: similarity search
Append this to qdrant_semantic_search.py or run as a separate snippet:
query = "How do I speed up my Postgres database?"q_emb = model.encode([query], convert_to_numpy=True)[0]
search_result = client.search(
collection_name=collection_name,
query_vector=q_emb.tolist(),
limit=3,
with_payload=True
)
for res in search_result:
print(f"ID: {res.id} Score: {res.score:.4f}")
print("Text:", res.payload.get("text"))
print("---")What to expect: The query about Postgres should return the Postgres performance document and possibly the vector-DB doc (if the embeddings put them closer). You can tune limit and score thresholds.
E. Optional: Improve relevance with reranking
Vector DB returns coarse candidates quickly; you can rerank the top-k using a dedicated cross-encoder or an LLM to get better ordering. This is common in production RAG pipelines (vector retrieval → reranker → LLM composition). Many tutorials (Qdrant and others) describe this pipeline pattern.
Performance tips, metrics, and monitoring (practical theory)
Index parameter tuning: HNSW has parameters like
ef_construction,m,ef(search param) that trade throughput and recall — tune them with real queries.Batch inserts: Bulk upload vectors to avoid per-point overhead.
Memory & CPU: ANN indices are memory heavy; some DBs support disk-based IVF + PQ to lower memory at the cost of latency.
Metrics to watch: QPS, P99 latency, recall@k, index build time, and RAM usage.
Observability: Log query latencies and top-k recall vs. a small ground-truth set for automatic regression checks.
How to pick the right DB — a practical checklist
Do you need managed serverless scaling? (→ Pinecone)
Do you want open-source control and easy local dev? (→ Qdrant / Weaviate / Chroma)
Already on Postgres and need ACID? (→ pgvector)
Do you need hybrid search (keyword + semantic)? (→ Elasticsearch, Weaviate, others)
Budget and infra: in-memory systems (Redis) are very fast but costly; Faiss + self-hosted can be cheaper but requires expertise.
What’s more to write now !!
Vector databases are the memory models of modern AI apps — they let your systems remember and understand meaning. Pick the right tool, measure results, and iterate. And hey — when your app starts recommending exactly what users want, resist the urge to whisper “I told you so” to your codebase.
Hope this blog clears some of your doubts about Vector Database. Thanks for reading this. Like, Share and Comment it for later reading.
Follow me on socials for more updates, behind-the-scenes work, and personal insights:
 | A guest post by
|