
Pixels, Patterns… but No Poetry? Why Today’s Smartest AIs Still Can’t “See” Like Us

Modern AI models that combine text and images (Multimodal Large Language Models, or MLLMs) have shown amazing abilities. For example, GPT-4 Vision or Google Gemini can caption complex photos, recognize objects, and even reason about scenes. But do they really see the world as we do? Recent research introduces a “Turing Eye Test” (TET)—a set of image puzzles that humans solve instantly but AI cannot. Think of it like the classic Turing Test for conversation, but applied to visual perception.
The Turing Eye Test: AI’s Visual IQ Exam
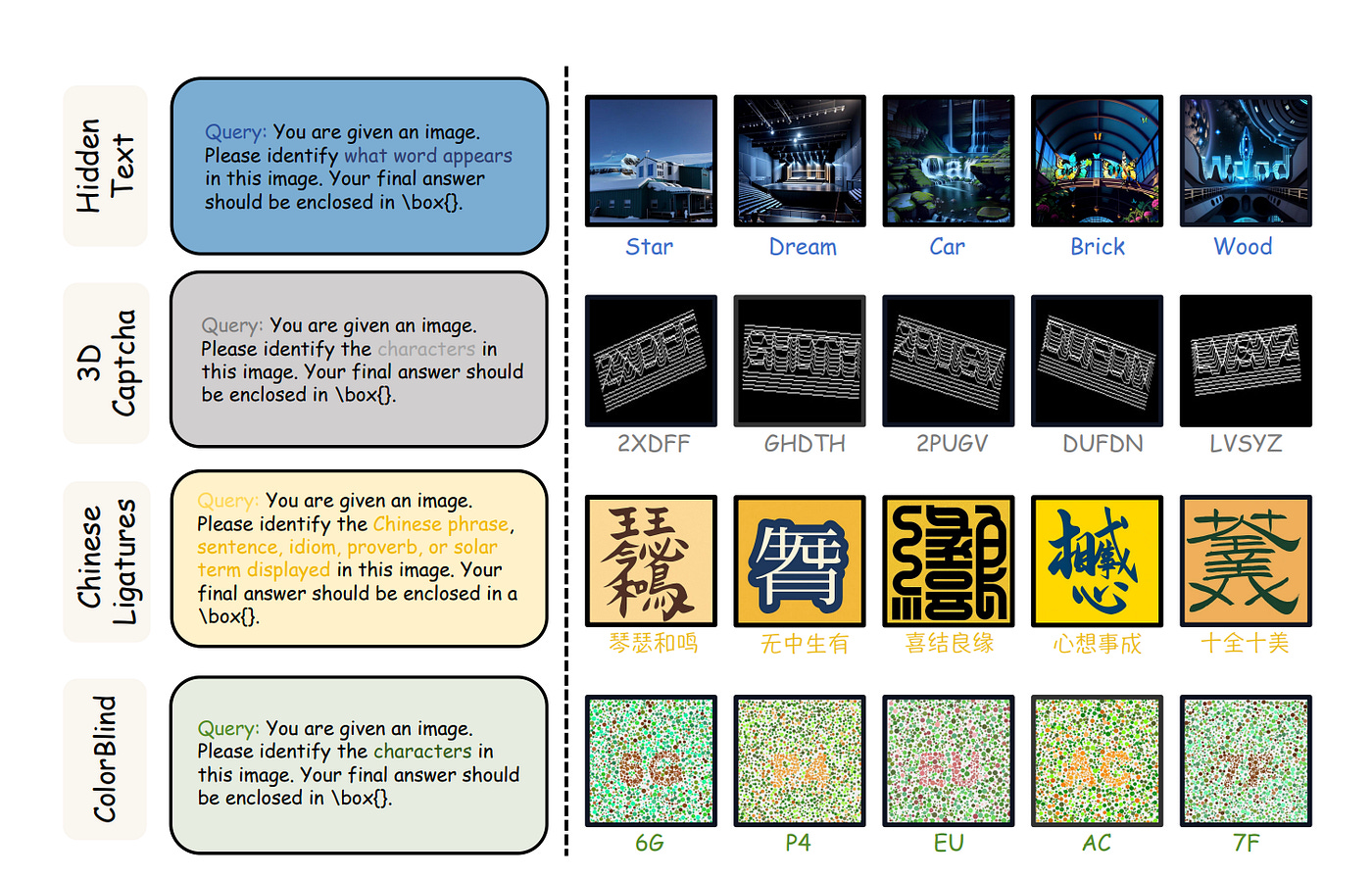
Unlike standard vision benchmarks, TET focuses purely on perception puzzles without relying on language hints. It defines four diagnostic tasks—images that are trivial for humans—to probe an AI’s visual understanding:
HiddenText: Scale-variant images where words are hidden as graphic shapes in a scene. For example, a city skyline might actually contain the word WORLD spelled out by the architecture.
3DCaptcha: Rotated 3D text puzzles with curved letters (like a CAPTCHA drawn in perspective), testing spatial reasoning.
ColorBlind: Color-dot illusion tests (like Ishihara plates) that hide numbers or symbols among distracting dots.
Chinese Ligatures: Intricate symbols formed by fusing multiple Chinese characters into a single glyph
Each of these puzzles is easy for a human—we use context and pattern recognition effortlessly—but extremely challenging for today’s AI.
HiddenText: Seeing Words in Pictures
HiddenText example: This city skyline conceals the word “WORLD” in its architectural shapes. A person can read the word quickly, but the state-of-the-art AI completely fails this task. The model might caption “tall buildings at night,” yet it ignores the hidden message. It has the raw pixels and patterns but doesn’t perceive the embedded text the way our brains do. In effect, the AI sees the picture but misses its poetry.
This highlights how current models can describe a scene yet miss an obvious hidden pattern. In short, AI has the pixels and patterns but no poetry in vision.
Complex Symbols and Color Tricks
Chinese Ligatures puzzle: This image merges several Chinese characters into one glyph. A human reader sees the phrase instantly; the AI does not. Likewise, 3D CAPTCHAs twist letters through space, and colorblind tests hide numbers in swirling dots.
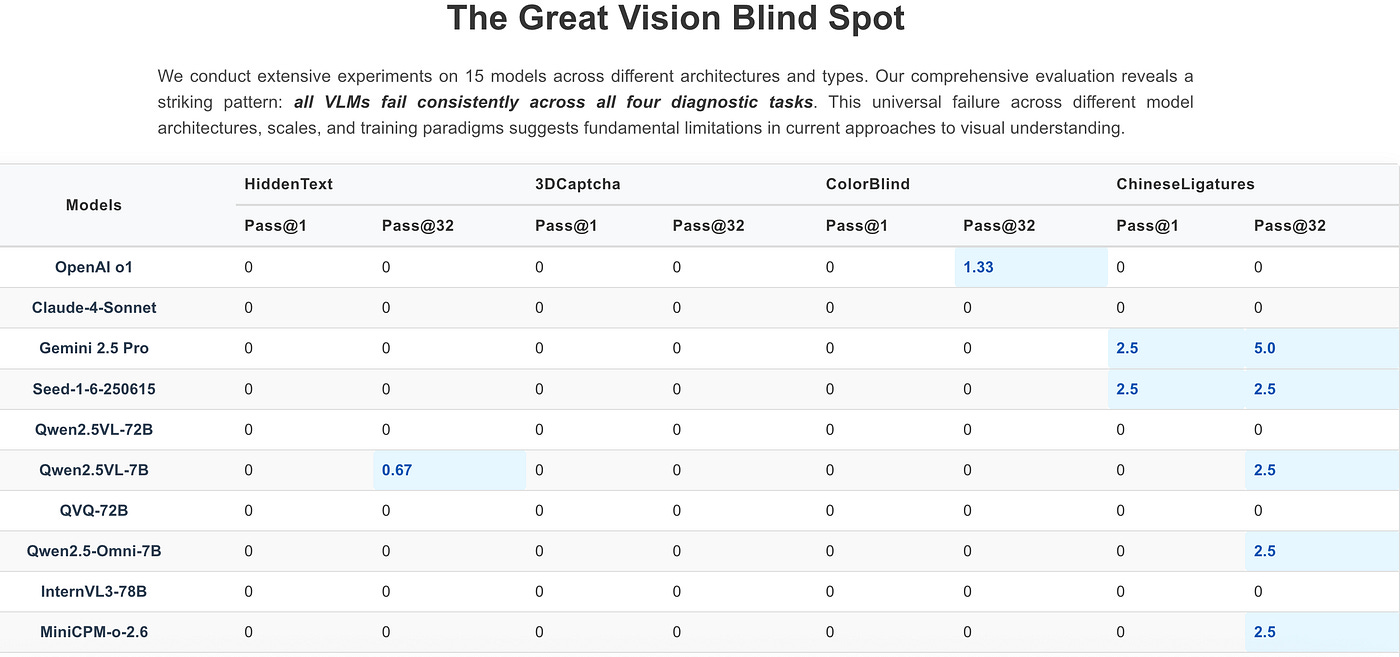
In each case, humans excel by grouping shapes and colors intuitively—for example, spotting a number in a field of colored dots without scanning every pixel—but the AI stumbles. In fact, every model tested failed consistently on these puzzles, showing this is a universal blind spot.
AI’s Great Vision Blind Spot
Extensive tests on 15 different models (GPT-4 Vision, Gemini, Claude, etc.) showed they all scored near-zero on the TET tasks. Even models that master image captioning or visual question answering collapse on these puzzles.
In contrast, humans solve TET nearly every time. As the authors note, AI may parse objects and text, but “does not perceive the world as humans do”—it ”has pixels and patterns, but lacks the poetic intuition of human vision.
Fixing the Eye, Not the Brain
Why do these models fail so badly? The key finding is that the vision encoder itself is the bottleneck. The researchers tried all the usual tricks—extra prompts, language-side fine-tuning — and saw no improvement. Only when they fine-tuned the vision encoder on the TET examples did the AI begin to succeed. In other words, teaching the model more text didn’t help it see better; retraining its “eyes” did.
Grad-CAM visualizations confirmed this: the model’s attention was often focused on irrelevant areas (like background textures) rather than the hidden content.
Why This Matters
For AI developers and students, these results are eye-opening. They highlight that even the most advanced multimodal models still lack some basic perceptual skills. To achieve human-like vision, we’ll need new approaches in visual learning. The authors plan to expand TET with more puzzles to help train models that truly understand images. In practical terms, a high score on image captioning alone doesn’t guarantee human-like perception. As one researcher quipped, the AI may have all the data, but it still lacks the “poetry” of human perception
Source: Gao et al., Pixels, Patterns, but No Poetry: To See The World like Humans
Paper references:
Thank you for reading this. Follow me here and on my socials for more such posts.
Follow me on socials:
Twitter: https://x.com/techwith_ram
Instagram:https://www.instagram.com/techwith.ram/
 | A guest post by
|