
Mixture of Recursions (MoR): Google DeepMind's Next Big Leap in AI
Say hello to Mixture of Recursions (MoR) — a completely new architecture that’s smaller, faster, smarter, and possibly… better than Transformers

In 2017, Google Brain dropped a paper that would redefine artificial intelligence forever — “Attention is All You Need.” It introduced the Transformer architecture, the backbone of every major large language model (LLM) today, from OpenAI's ChatGPT to Anthropic's Claude, Meta’s LLaMA, Google’s Gemini, and even video-generation systems like Sora.
Fast forward to 2025 — the same brilliance from Google’s research powerhouse, DeepMind, may have just done it again.
Say hello to Mixture of Recursions (MoR) — a completely new architecture that’s smaller, faster, smarter, and possibly… better than Transformers.
Research paper: https://arxiv.org/pdf/2507.10524v1
What is Mixture of Recursions (MoR)?
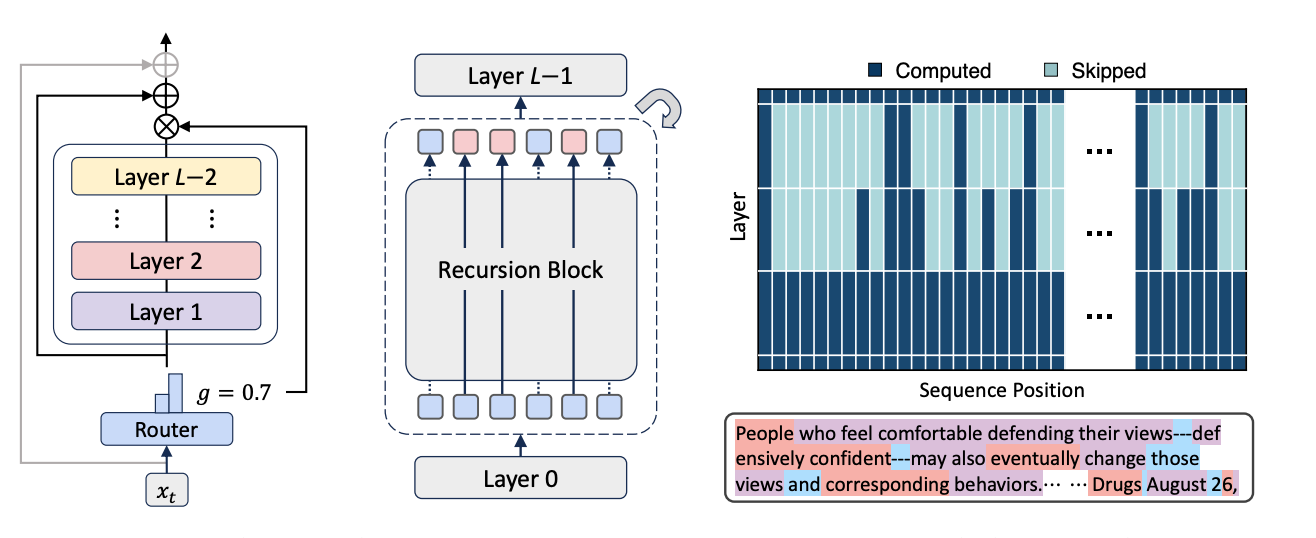
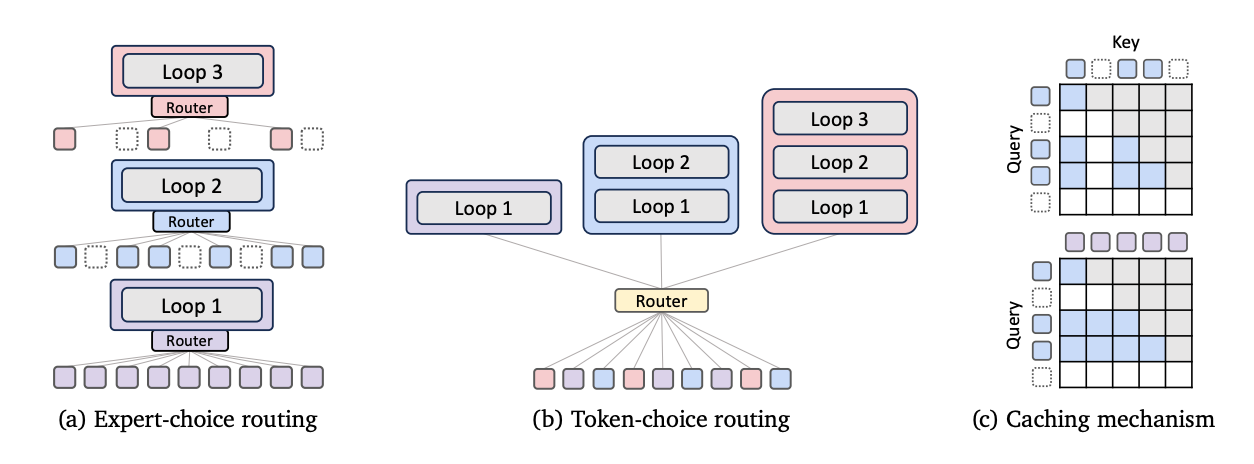
Mixture of Recursions, or MoR, is DeepMind’s fresh take on building large language models. But unlike the traditional Transformers that send every token through every single layer, MoR thinks more like a human — some words are simple, others complex, so why treat them all the same?
It introduces a smart, recursive loop for token processing, powered by a token-level router. This router decides:
Which tokens need more computation
Which ones can “exit early”
Which should be processed again — like taking another lap on the reasoning track
In short, easy words leave early, complex ones take a deeper route — intelligently, efficiently, and recursively.
Why MoR Could Be the Future of AI
MoR brings some serious upgrades to the AI game:
2x Faster Inference
While Transformers crunch every token through 100+ layers, MoR takes a shortcut — not by cutting corners, but by being smart about effort. This slashes inference time dramatically.
50% Lower Memory Footprint
MoR only stores what's necessary — active tokens in cache. And if RAM is tight, the same memory can be reused across loops with minimal accuracy loss.
Half the Training Compute
Training LLMs is expensive. MoR reduces training compute by nearly 50%, a massive cost saving for companies and researchers alike.
Better Accuracy with Smaller Models
Here’s the jaw-drop moment:
A MoR model with just 118M parameters outperforms a Transformer with 315M parameters on few-shot tasks.
In other words: Smaller model. Bigger brains.How Does MoR Work?
At its core, MoR introduces controlled recursion into language models:
Tokens are routed based on their complexity.
Simple tokens exit early.
Complex tokens take another loop (or more).
A router makes real-time decisions — like a traffic cop for AI processing.
This loop-based control allows the model to think, re-think, and plan without wasting resources.
It’s almost like giving your AI a brain that knows when to think harder.
Rethinking AI Reasoning
This isn’t just about speed. MoR represents a fundamental shift in how LLMs reason.
With Transformers, every task goes through 100+ layers — whether it's simple arithmetic or multi-step reasoning.
With MoR, planning becomes part of the architecture. The model itself decides how many steps to take based on the complexity of the task — just like how humans might solve a puzzle in 3 moves or 10, depending on the difficulty.
Is This the End of Transformers?
Not quite. Transformers are still powerful, well-optimized, and reliable. But history tells us that AI is constantly evolving.
RNNs and LSTMs ruled the 2010s.
Transformers dominated the 2020s.
And now, MoR might just define the 2030s and beyond.
Just as Transformers replaced older architectures, MoR might be next in line — especially as we demand faster, leaner, more intelligent systems.
Why It Matters (Now More Than Ever)
In a world rapidly adopting AI — from search to self-driving, content creation to enterprise automation — efficiency is key. AI needs to run:
On mobile devices
On the edge
In real-time
At scale
MoR makes that more feasible. It unlocks powerful models that are small enough to run fast, yet smart enough to deliver great results.
Final Thoughts
Google DeepMind has once again thrown down the gauntlet. From inventing the Transformer to now potentially surpassing it with Mixture of Recursions, they’re redefining how we think about AI architecture.
This isn’t just an upgrade — it’s a new mindset:
“Don’t overthink everything. Only think when it matters.”
And that may just be the future of intelligence — human or artificial.
Thanks for reading this. Subscribe to get more updates like this.
Follow me on socials:
Twitter: https://x.com/techwith_ram
Instagram:https://www.instagram.com/techwith.ram/
 | A guest post by
|